반응형

최근 SK하이닉스에서 Processing in memory, PIM 기술이 적용된 메모리 반도체 샘플을 첫 공개했었는데요. PIM에 대해서 심도있게 알아보도록 하겠습니다.
[질문 1]. Processing in memory, PIM 기술에 대해서 설명해보세요.
PIM은 Processing in memory로 메모리 반도체 내에서 processing 연산 기능이 가능한 반도체를 의미합니다. 기존의 컴퓨터 시스템은 폰노이만(Von Neumann) 아키텍처를 따르고 있습니다. 폰노이만 아키텍처는 메모리가 명령어 및 연산자의 저장을 담당합니다. 그리고 CPU와 같은 프로세서는 메모리에 저장된 명령어나 연산자를 불러와 연산을 수행합니다. 기존 아키텍처에서 메모리 반도체는 정보의 입출력에 대한 저장만 수행했습니다. PIM 기술은 메모리 반도체에서 컴퓨터 시스템 내의 역할을 확대함으로써 기존 프로세서가 담당하는 연산 일부를 메모리 반도체에서 수행할 수 있는 기술을 의미합니다.
[꼬리 1-1]. PIM 기술 적용함에 따른 장점에 대해서 설명해보세요.
미래 기술 중 하나인 인공지능 AI의 비중이 점점 커지고 있습니다. PIM 기술은 AI 연산에 최적화된 반도체입니다. AI 기술을 구현하기 위해서 프로세서의 연산 처리 속도는 점점 빨라지고 있으며 프로세서의 연산속도를 메모리가 따라가지 못하게 되면서 메모리 입출력 속도 제한으로 전체 AI 연산의 성능 제약이 발생하게 되었습니다. 프로세서에서 연산을 하기 위해서는 메모리에 저장된 데이터를 불러와 처리 이후에 다시 결과를 저장해야 합니다. 하지만 프로세서와 메모리 사이의 대역폭의 제약이 있다 보니 전체적인 AI연산이 느려지게 됩니다. 따라서 PIM 기술을 적용하면 메모리에서 일부 연산을 수행함으로써 프로세서와 데이터가 주고 받는 데이터의 양을 줄임으로써 전체적인 성능을 향상시킬 수 있게 되었습니다. 그리고 메모리와 프로세서가 데이터를 읽고/저장하는데 있어서 많은 에너지가 소모되는데, PIM 기술이 적용되면 데이터 전송에 대한 에너지 소모도 절감할 수 있습니다.
[꼬리 1-2]. PIM 기술의 도입 이유를 Roofline model을 이용하여 설명해주세요.
Roofline model은 알고리즘의 메모리전송량과 계산량의 비율로 달성가능한 최대 성능(Roofline)을 표현하는 그래프입니다. x축인 연산강도(Operational intensity)는 알고리즘의 총 연산자수와 메모리 전송량의 비율을 나타내며, intensity가 클수록 전송량 대비 계산량이 많은 것을 의미합니다. Roofline을 통해 컴퓨팅 시세틈의 성능제약이 어떤 원인에서 비롯되었는지 파악할 수 있습니다. 선형적인 roofline을 갖는 영역은 컴퓨팅 연산능력이 증가하는 부분으로 메모리 bandwidth, 대역폭에 따른 성능의 bottleneck이 나타나며, 일정한 값을 가지는 영역은 프로세서의 연산속도가 bottleneck 됩니다. 이러한 성능의 bottleneck 이슈를 개선하기 위해서 메모리에서 일부 연산을 수행함으로써 프로세서와 메모리가 주고 받는 데이터 양을 줄이게 된다면, 성능 bottleneck 현상을 완화 할 것이라는 기대로 PIM 기술이 도입되었습니다.

■ Tip. 인공지능 연산에 중요한 딥러닝 알고리즘으로 Roofline을 분류하자면, CNN은 프로세서의 연산속도 개선이 중요합니다. 그래서 평평한 영역의 Roofline 개선이 요구됩니다. 음성인식에 주로 사활용되는 RNN이나 맞춤서비스에 활용되는 DNN은 메모리 대역폭의 개선이 필요하기에, 선형적인 영역의 성능개선이 요구됩니다. CNN은 DNN, RNN에 비해 메모리 데이터를 불러와 수많은 연산을 수행하기에 메모리 재사용률이 높습니다. 따라서 컴퓨팅 연산속도가 시스템 성능향상에서 매우 중요한 요인입니다.
[질문 2]. PIM 기술 구현 방법 중 하나인 Process-near-memory에 대해서 설명해보세요.
Processing in memory, PIM 기술은 Processing-near-memory와 Processing-in-chip 두 가지의 방법으로 분류됩니다. Processing-near-memory는 이름 그대로 메모리 칩 내부에 연산기능을 하는 부분이 포함된 것이 아니라 메모리 제작 이후 패키징 공정에서 별도의 연산을 담당하는 장치를 포함시켜 필요한 연산을 수행하는 개념입니다. 칩을 제작하고 외부에 연산 Logic을 추가하여 PIM 기술을 구현합니다. DRAM을 예로 들 때, DRAM 칩은 노트북, 스마트폰, TV 등 다양한 제품에 탑재되며, 원가 절감이 중요합니다. 그래서 EUV 기술 도입 같이 미세화에 힘을 쏟는 것입니다. PIM 기술을 위해 DRAM에 연산 Logic을 추가한다면 chip size가 커지게 되고 원가가 높아져 수익성이 낮아지는 이슈가 발생합니다. PIM 기능을 요구하지 않는 응용분야에서는 PIM 기능은 원가상승을 의미하며, 각 응용마다 연산의 형태가 달라 모든 응용의 요구를 충족하는 연산기능을 추가하기도 힘듭니다. 그래서 PIM 기능을 요구하는 각각의 응용에 맞추어 로직 프로세서를 추가하여 부담을 최소화하는 방향으로 기술이 발달 되고 있습니다.
[꼬리 2-1]. Processing-near-memory에 DRAM에 연산기능은 어떻게 추가하는 것인지 설명해주세요.
DRAM은 채널 효율성과 집적도를 높이기 위해 PCB 보드 위에 DRAM Chip을 부착한 DIMM 형태로 제작됩니다. DIMM PCB 여유 공간이 많아 이곳에 연산 로직프로세서를 추가하는 것입니다. 기존의 DIMM에서도 신뢰성 강화를 위한 ECC Chip, Data 및 명령어 제어를 위한 별도의 칩이 탑재된 제품을 볼 수 있습니다. 따라서 연산을 위한 칩 추가가 상대적으로 어렵지 않고, PIM용 Logic chip을 추가함으로써 성능향상을 시킬 수 있습니다.
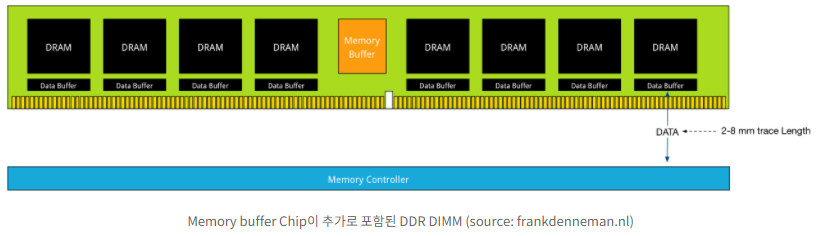
[꼬리 2-2]. High Bandwidth Memory, HBM에 대해서 설명해주세요.
HBM은 Throguh Silicon Via, TSV 공법을 활용해 DRAM 칩과 오비 패키징 사이의 통신 속도와 대역폭을 높인 메모리 인터페이스입니다. TSV를 통해 모인 Data가 외부로 나가기 전에 맨 아래의 로직에서 순서를 정렬한 후 보내집니다. HBM은 딥러닝 응용에서 주로 활용되는 고성능 메모리입니다. 때문에 딥러닝 응용의 전체적인 성능을 향상시키는 PIM에서도 적용하려고 노력하고 있습니다.

[미래 AI반도체 시장 주도하라] HBM-PIM 메모리
신경망처리장치기술로 인한 학습과 추론 등 AI 구현에 특화된 고성능, 저전력 시스템 반도체인 AI반도체가 대두되고 있습니다. IoT 산업의 도래로 모바일, 자동차, 가전 등 모든 산업분야를 망라하고 AI 반도체 수요가 급증할 것으로 예상됩니다. 최근 정부는 초기 단계인 AI반도체 시장을 선점함으로써 2030년 전세계시장 점유율 20% 달성 계획을 목표로 하여 대폭 지원에 나서고 있습니다.
인공지능의 핵심은 딥러닝 알고리즘입니다. 따라서 미래 반도체 산업의 핵심은 딥러닝 알고리즘 연산에 최적화된 뉴로모픽 시스템반도체의 개발이라고 생각합니다. 특히 삼성전자는 딥러닝 알고리즘 연산에 최적화된 NPU 기술을 육성하여 시스템반도체 산업 1위를 목표로 하고 있습니다. 여기서 뉴로모픽 시스템은 인간의 뇌 구조를 하드웨어적으로 모방한 기술로 병렬구조를 가진 인공지능 알고리즘을 빠르게 구현할 수 있습니다.
하지만 신경세포 간의 접합부분인 시냅스를 모방하는데 많은 소자가 요구되고, 이는 반도체 chip size의 증가와 전력소모가 증가하는 이슈가 존재합니다. 그래서 시냅스를 모방하는 시냅스 소자의 연구가 선행되어야 하며 이를 시스템에 적용해야 한다고 생각합니다.
최근 삼성전자는 세계 최초로 메모리반도체와 인공지능 프로세서를 하나로 결합한 HBM-PIM 기술을 개발했습니다. PIM 기술은 전자기기의 두뇌역할인 CPU의 영역을 메모리 반도체가 일부 처리하는 기술로 DRAM에 AI 특화 연산 기능을 적용시킨 반도체입니다. 이를 AI 시스템에 탑재할 경우 기존 성능대비 2배 이상 높아지게 되고, 시스템 에너지는 70% 이상 감소하는 우수한 성능을 발표했습니다.
[질문 3]. PIM 기술 구현 방법 중 하나인 Process-in-chip 에 대해서 설명해보세요.
Processing in chip 기술은 데이터가 저장된 DRAM 셀 근처에 연산을 수행하는 로직 프로세서를 포함하는 방법입니다. Processing-near-memory는 기존의 프로세서의 역할을 DRAM 패키지로 가져오는 offloading의 성격이 크기 때문에 메모리대역폭 절감이라는 목표를 달성할 수 있었습니다. 하지만 효율성 관점에서는 큰 개선이 없다는 단점이 존재합니다. Processing-in-chip 방식은 data의 입출력과 동시에 필요한 연산이 이루어질 수 있습니다. 그로 인해, Processing-near-memory 방식보다 효율성이 극대화됩니다. 물론 DRAM 칩 내부에 연산을 위한 Logic processor를 추가하는 기술력과 비용이 추가되기 때문에 전체 응용분야의 요구를 충족시키는 연산을 구현하기 어렵고, 필요한 특정 연산에 최적화된 로직을 선택해야만 합니다.
'Processing-In-Memory, PIM 기술은 메모리 반도체가 프로세서의 연산 일부를 담당함으로써 Processing의 부담을 나누어 갖고, 에너지 절감 및 연산 시간을 단축할 수 있는 효과를 가지고 있다' 정도로만 숙지하시면 될 것 같습니다.
오늘 하루도 고생 많으셨습니다.
충성! from 교관 홍딴딴
반응형
그리드형(광고전용)
'반도체사관학교 훈련과정 > 제품' 카테고리의 다른 글
| [DRAM #2] "고대역폭 메모리 HBM, RCAT, DCAT, 차세대 DRAM" (5) | 2022.03.02 |
|---|---|
| [DRAM #1] "Dynamic Random Access Memory, D램에 대해서 설명하세요" (14) | 2022.03.02 |
| [DDR & LPDDR] "#DRAM, DDR & LPDDR에 대해서 설명해보세요" (0) | 2022.03.02 |
| [전력반도체] "Power Module IC, PMIC에 대해서 설명하세요" (0) | 2022.02.09 |
| [반도체] "CMOS Image Sensor, CIS vs CCD에 대해서 설명해보세요. (0) | 2022.02.09 |








최근댓글